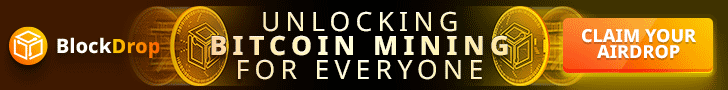

We identified Bitcoin Cash developer Gavin Andresen as being the real Satoshi Nakamoto using Eder’s bootstrapped stylometry method. This finding supports our previous article on the topic that also identified Gavin as Satoshi using Principal Component Analysis and Burrows’ delta.
Stylometry is a set of methods that aim to identify an unknown author by statistically deciphering their style using statistics. A famous example recently occurred with JK Rowling’s pen name Robert Galbraith being uncovered thanks to stylometry methods.
Satoshi Nakamoto is an assumed pseudonym which the inventor of Bitcoin gave himself as to disguise his identity, it’s thanks to Satoshi that we now see hundreds of bitcoin exchanges in the marketplace.
There have been many attempts to uncover his identity but there remains no concrete evidence to this date. A big part of this failure can be attributed to the lack of convergence validity in the stylometry field.
Joseph Rudman, a linguist at Carnegie Mellon university, wrote an excellent paper on the faults of stylometry titled The state of non-traditional authorship attribution studies 2012: Some problems and solutions. This paper pointed out that stylometrics often cherry pick results due to their algorithms producing vastly different results when slightly tweaked.

Our previous study had elements of cherry picking in that we would get different results when we changed our model from using correlations to covariances. Overwhelmingly our model clustered Gavin Andresen with Satoshi but when we used covariances our model would load the Satoshi whitepaper onto a paper by Wei Dai.
Maciej Eder created a bootstrapping method specifically designed to overcome the problem of cherry picking elements like Most Frequent Words (MFW). The approach uses Burrows’ delta to find a difference between two texts, but also uses random sampling of MFW ranges so as to output more robust results.
Burrows’ delta is basically a manhattan distance of z-scores which is sourced from a list of top words used in an entire corpus.
We used Eder’s bootstrapped delta to see if it would uncover the identity of Satoshi Nakamoto. We generated the z-score table using means and standard deviations sourced from 20,000 English texts from the Gutenberg corpus.
We then calculated the random samples for the manhattan distance algorithm for MFWs between 1 and 5,000.
This was calculated by comparing a list of authors associated with Bitcoin against the original Bitcoin whitepaper. Finally, we used a kNN approach to sort the mean distances in order so that we could see who had the most similar writing style to Satoshi in our experiment.
We found that the first nearest neighbour was Satoshi’s email texts followed by 3 of Gavin Andresen’s GitHub documents and then followed by Satoshi’s forum texts. These findings are quite reasonable because not only do they validate the links between the Satoshi whitepaper-emails-forums but they also cluster Gavin as the likely author. It’s also of interest that Gavin’s style was so much like Satoshi’s whitepaper that he beat Satoshi himself with the forum texts!
A limitation of the current study is that it could be measuring the style of genre rather than that of authorship. We may need to come up with a way to standardise the datasets to remove any noise that may come from such a systematic bias. One way could be to remove pronouns from the analysis because these could correlate with the style of an academic paper.
Also, we’ve already started work on our code stylometry machine that will analyse Satoshi’s C++ style of programming. We’ve already found using Most Frequent Character (MFC) n-grams that Gavin also has a similar programming style to Satoshi.
A comparison of some of the texts shows clearly that Gavin’s GitHub blogs have similar low distances to the whitepaper as does Satoshi’s emails/forums. This chart also shows that Gavin’s GitHub posts #4 has a low volatility and even beats the Satoshi email texts on many occasions.
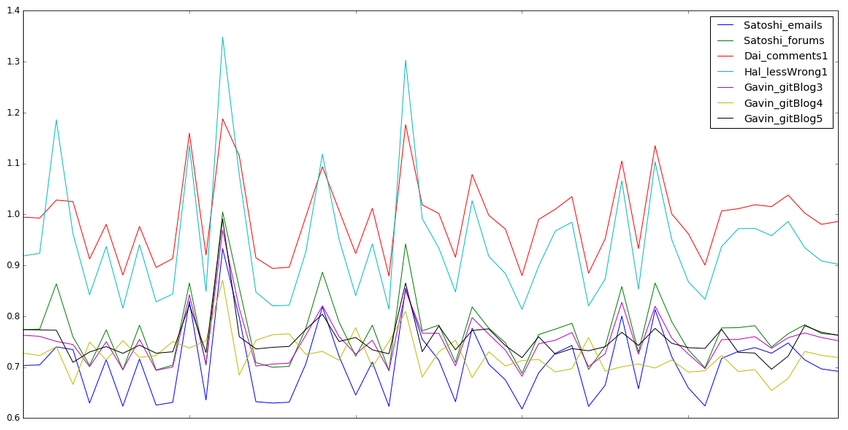 We discretized the distances to analyze the different patterns in the heatmaps. One can clearly see Gavin’s GitHub blogs having low distances. You can also see that Gavin’s regular blog posts (sorted by year) do not load onto the whitepaper. But it’s also worth mentioning that with the heavily discretized heatmap (top-right) shows that only Gavin and Satoshi reach the high pink level (~0.7) of having a low distance with the whitepaper.
We discretized the distances to analyze the different patterns in the heatmaps. One can clearly see Gavin’s GitHub blogs having low distances. You can also see that Gavin’s regular blog posts (sorted by year) do not load onto the whitepaper. But it’s also worth mentioning that with the heavily discretized heatmap (top-right) shows that only Gavin and Satoshi reach the high pink level (~0.7) of having a low distance with the whitepaper.
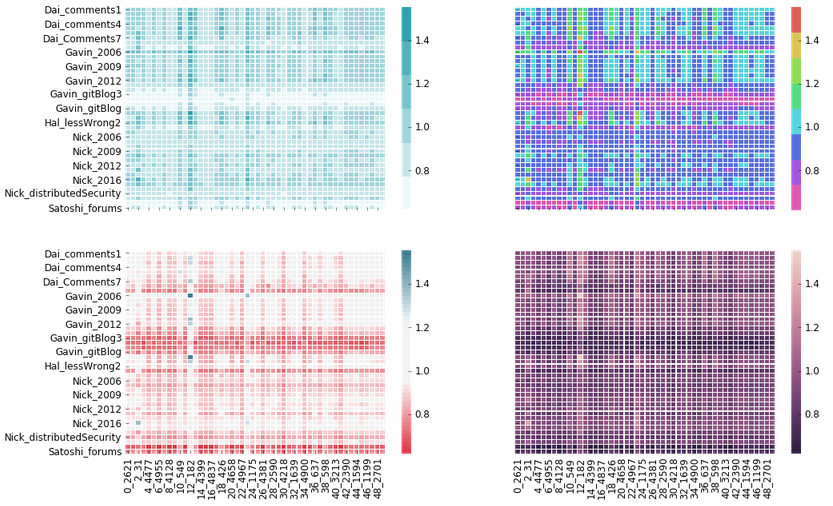
The heat map below shows more clearly the Bitcoin texts we analyzed. Our columns are numbered x_y with x being the iteration number and y the number of MFWs used. The column 49_2728 means that it was the 49th bootstrapped iteration and it used 2,728 MFWs for each textual comparison with the whitepaper. This chart only shows 49 iterations but our final analysis used 2,500 iterations to maximize our estimates of the population.
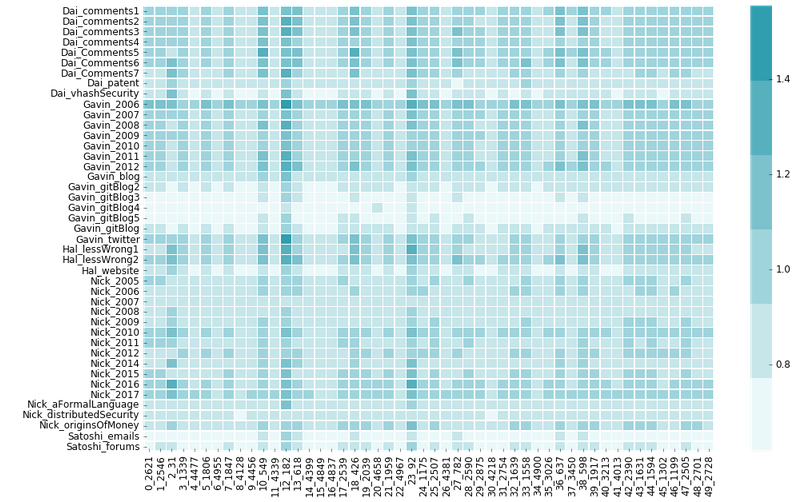
Our final result shows a table of z-scores of means and standard deviations of the 2,500 samples that were collected for each textual comparison with the whitepaper. The chart shows that Gavin’s GitHub blog #4 not only has the 2nd lowest distance to the whitepaper but also has one of the lowest SDS in the entire corpus, suggesting that such a position is accurate in our knn methodology. One can not ignore that Eder’s bootstrapped delta not only validates the connection between all 3 Satoshi texts but also loads Gavin Andresen in the top 5 results above Satoshi’s forum posts.



